Memories
GitHub: divyekant/memories · Website: memories.divyekant.com
What it does
Section titled “What it does”AI assistants lose all context when a session ends. Memories gives them persistent, searchable memory that survives across sessions, projects, and machines. It runs locally as a Docker service, provides sub-50ms hybrid search fusing five signals (BM25 keyword, vector similarity, recency, feedback, confidence), and works with any AI client that supports MCP or REST — Claude Code, Claude Desktop, Claude Chat, Codex, Cursor, ChatGPT, OpenClaw, and anything that can call HTTP.
Graph-aware search automatically builds a relationship graph between memories. When extraction stores a new memory, it creates related_to edges linking it to similar existing memories. Search uses Personalized PageRank (PPR) for multi-hop traversal, enriches results with graph-connected neighbors, and injects graph-only results into top-k via reserved slot injection (HopRAG-style). Every result carries match_type, base_rrf_score, graph_support, and graph_via annotations. Benchmarks show +20% answer hit rate on 2-hop questions and +15.3% on 3-hop support chain recall — with zero regressions.
A temporal reasoning engine tracks when source content was created via an ISO 8601 document_at field, separate from system timestamps. Updates now preserve history: the old memory is archived with a supersedes link instead of being deleted, and an is_latest flag distinguishes current versions from superseded ones. Date-range search via since/until filters works across all search methods. Reinforcement tracking is separated from content updates via last_reinforced_at.
Multi-backend routing lets a single agent session talk to multiple Memories instances simultaneously. Configure scenario-based routing (dev+prod, personal+shared, or single instance) via ~/.config/memories/backends.yaml, with parallel search fan-out, exact-text dedup, and _backend provenance tags on every result. Extract routing directs new memories to the right instance automatically. No config file means env-var mode — fully backward compatible.
An operator workbench lets you create, edit, merge, and bulk-manage memories with dry-run extraction, per-fact approval, and conflict resolution. Lifecycle policies enforce per-prefix TTL and confidence-based auto-archive with operator-visible evidence. A full audit trail tracks every mutation with lifecycle timelines and evidence strength badges. Quality benchmarks via a three-tier eval framework (Tool, System, Scenario) with MuSiQue and Voltis benchmarks provide regression tracking per release.
For Claude Code, a native plugin packages the full 12-hook lifecycle, skills, and CLAUDE.md into a single installable unit with auto-update. Hooks cover session start, every prompt, after response, pre/post-compact, subagent start/stop, tool use, tool observation, file write guard, config change, and session end — making memory fully automatic. An interactive /memories:setup skill provisions the Docker backend and MCP config in one step, with a standalone docker-compose.standalone.yml for zero-clone deployment (no git clone needed). Extraction fires unconditionally — the AUDN LLM decides what’s worth keeping, not a keyword filter. Codex and Cursor get the same hook scripts; any other client connects via MCP or REST.
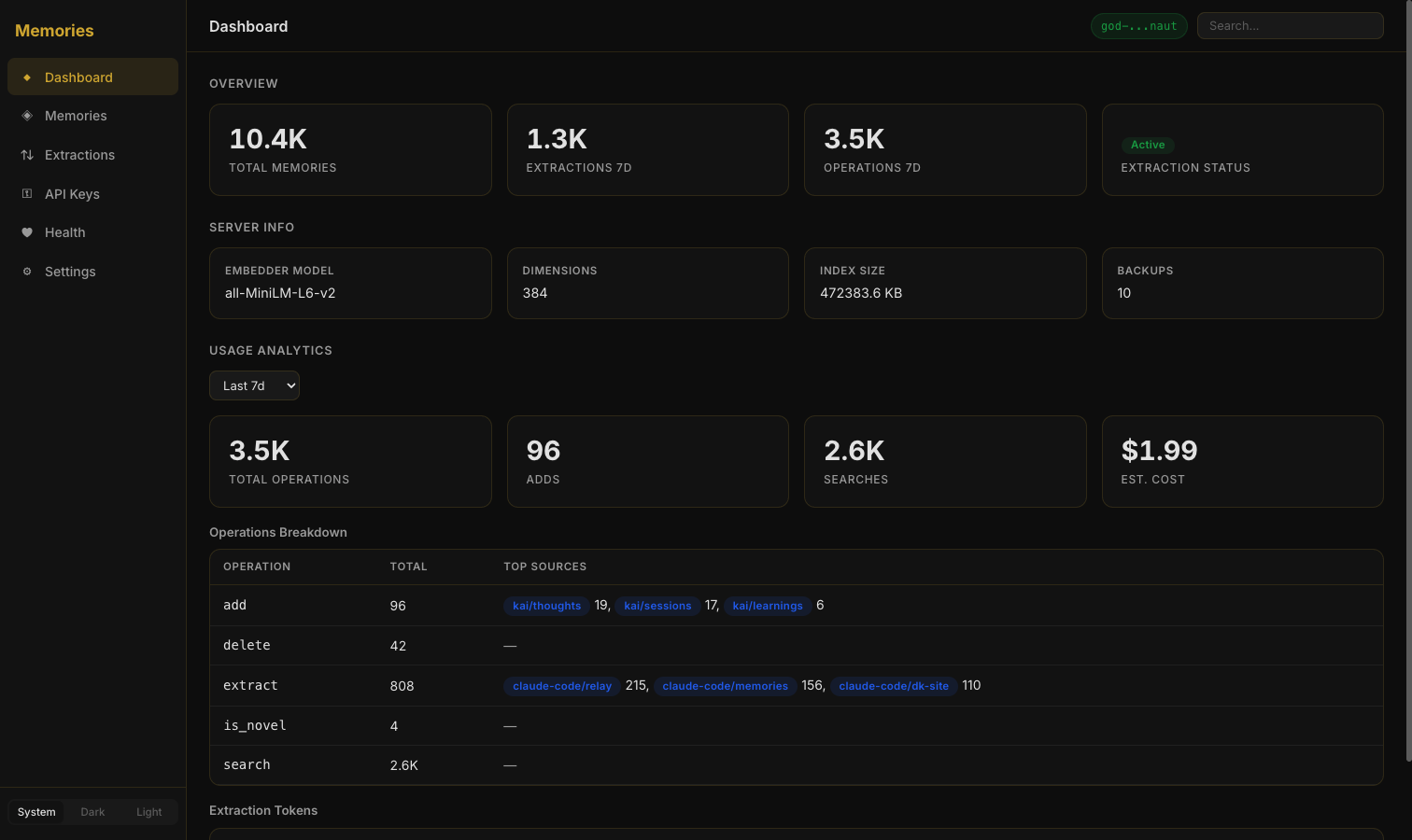
A full CLI with 30+ commands provides terminal-native access to every API endpoint with TTY-aware output. Multi-auth with prefix-scoped API keys lets teams share a single instance with isolated access. The Web Dashboard provides a full management interface.
Key Features
Section titled “Key Features”- Graph-aware search — Automatic relationship graph between memories with PPR-based multi-hop traversal, link-expanded retrieval, reserved slot injection (HopRAG-style), and per-result annotations (
match_type,graph_support,graph_via) — +20% on 2-hop, +15.3% on 3-hop recall - Temporal reasoning — ISO 8601
document_atdates, version preservation withsupersedeslinks (no hard-delete on update),is_latestflag,since/untildate-range filters, andlast_reinforced_attracking separate from content updates - Multi-backend routing — One agent session searches multiple Memories instances in parallel with scenario-based config (dev+prod, personal+shared, single), exact-text dedup,
_backendprovenance tags, and extract routing — fully backward compatible - 5-signal hybrid search — BM25 keyword + vector similarity + recency + feedback + confidence, fused with Reciprocal Rank Fusion, under 50ms
- Operator workbench — Create, inline edit, merge, pin/archive with undo, bulk actions (archive/delete/retag/re-source/merge), extraction trigger with dry-run preview and per-fact approve/reject
- Feedback-weighted ranking — Search learns from
useful/not_usefulsignals over time - Lifecycle policies — Per-prefix TTL and confidence-based auto-archive with operator-visible evidence
- Full audit trail — Every mutation tracked, lifecycle timeline in UI, evidence strength badges
- Three-tier eval framework — Tool, System (agent + MCP), and Scenario (conversational) evaluation with MuSiQue multi-hop benchmarks (1,165 questions) and Voltis synthetic benchmarks — parallel eval workers with model comparison
- Conflict resolution — Detects contradictory memories with Keep A / Keep B / Merge / Defer options and soft archive
- AUDN extraction pipeline — Automatically classifies facts as Add, Update, Delete, or Noop to keep memory clean over time
- Memories Skill — Three responsibilities: Read (proactive recall), Write (hybrid
memory_add+memory_extract), and Maintain (AUDN-driven lifecycle cleanup). +43% eval improvement over baseline memory_extracttool — Synchronous MCP tool that analyzes conversations and classifies facts through the AUDN loop before storing- Web Dashboard — Dashboard (stats, extraction metrics, server info), Memories (tabbed detail: Overview / Lifecycle / Links), Extractions, Health (conflicts, problem queries, stale memories), API Keys, Settings — dark/light/system theme
- Multi-auth — Prefix-scoped API keys with three role tiers (read-only, read-write, admin) for team-safe shared instances
- Full CLI — 30+ commands with TTY auto-detection, layered config (flags > config file > env vars > defaults), shell completion, batch operations, and JSON/pretty output modes
- Multi-client support — MCP for Claude Code, Claude Desktop, Codex, Cursor; REST API for ChatGPT, Claude Chat, OpenClaw, and anything else
- Claude Code integration — Native plugin with 12-hook lifecycle (session start, every prompt, after response, pre/post-compact, subagent start/stop, tool use, tool observation, file write guard, config change, session end), interactive
/memories:setupprovisioning, subagent memory injection, unconditional extraction, and auto-update via dk-marketplace - Novelty detection — Checks if information is already known before storing, preventing duplicates
- NDJSON export/import — Filtered export with date ranges, smart dedup import, source remapping for migration or cross-instance sync
- Auto-backups — Snapshots after every write, with optional cron and Google Drive/S3 off-site backup
- ONNX Runtime inference — Same model quality as PyTorch (all-MiniLM-L6-v2) in a 68% smaller Docker image
- Extraction providers — Anthropic, OpenAI, ChatGPT Subscription, Ollama, or skip entirely
How it fits
Section titled “How it fits”Memories is the foundational persistence layer of the Arkos ecosystem. Carto stores its codebase index in Memories. Learning stores failure-fix patterns in Memories. Hermes writes generated documentation entries to Memories. Any tool that needs to remember something across sessions uses Memories as its backend.
Quick Start
Section titled “Quick Start”Recommended: Claude Code plugin (single-step setup)
# 1. Start the backend (no git clone needed)curl -fsSL https://github.com/divyekant/memories/raw/main/docker-compose.standalone.yml \ -o docker-compose.standalone.ymldocker compose -f docker-compose.standalone.yml up -d
# 2. Install the CC plugin and run interactive setup# (plugin auto-loads hooks, skills, and CLAUDE.md)# In Claude Code, run: /memories:setupManual setup:
# Clone and startgit clone https://github.com/divyekant/memories.gitcd memoriesdocker compose -f docker-compose.snippet.yml up -d
# Verifycurl http://localhost:8900/health
# Add a memory (REST)curl -X POST http://localhost:8900/memory/add \ -H "Content-Type: application/json" \ -d '{"text": "Always use TypeScript strict mode", "source": "standards.md"}'
# Search (REST)curl -X POST http://localhost:8900/search \ -H "Content-Type: application/json" \ -d '{"query": "TypeScript config", "k": 3, "hybrid": true}'
# Or use the CLImemories add "Always use TypeScript strict mode" --source standards.mdmemories search "TypeScript config" --hybridmemories list --source standards.mdmemories export -o backup.jsonlThe service runs at http://localhost:8900. API docs at /docs, web dashboard at /ui.
Architecture
Section titled “Architecture”AI Client (Claude Code, Claude Desktop, Codex, Cursor, ChatGPT, OpenClaw) | |-- Claude Code Plugin (12 hooks + skills + CLAUDE.md, auto-update) |-- MCP protocol (Claude Code / Desktop / Codex / Cursor) |-- REST API (everything else) vMCP Server (mcp-server/index.js) |-- Multi-backend proxy routing (Promise.allSettled fan-out) |-- backends.yaml config (scenario routing, env var interpolation) vMemories Service(s) (Docker :8900, or multiple instances) |-- FastAPI REST API |-- Hybrid Search (vector + BM25, 5-signal RRF fusion) |-- Graph-Aware Search (auto-linking, PPR scoring, link-expanded retrieval) |-- Temporal Reasoning (document_at, version preservation, date-range filters) |-- Markdown-aware chunking |-- Event Bus (SSE stream + webhook delivery) |-- Audit Log (append-only trail) |-- Memory Relationships (bidirectional adjacency index, scope-safe subgraph filtering) |-- Confidence Decay (time-based relevance attenuation) |-- Auto-backups vPersistent Storage (data/) |-- Qdrant vector store (embeddings + metadata) |-- metadata.json (memory text + metadata) |-- backups/ (auto, keeps last 10)Multi-backend routing is handled at the MCP server layer. The proxy reads ~/.config/memories/backends.yaml and fans out search requests to all configured backends using Promise.allSettled(), deduplicates results by exact text match, and tags each result with its _backend provenance. Extract routing directs new memories to the appropriate backend based on scenario config. Three built-in scenarios cover common setups: dev+prod (search both, extract to dev), personal+shared (search both, extract to personal), and single instance (default). Environment variable interpolation keeps API keys out of config files. No config file means env-var mode with unchanged behavior — fully backward compatible.
Multi-auth middleware enforces prefix-scoped API keys at three tiers: read-only (search and list within allowed prefixes), read-write (add, update, delete within allowed prefixes), and admin (full access including key management, backups, and usage stats).
The engine maintains a Qdrant vector store alongside a BM25 keyword index. Search queries hit both and results are fused using 5-signal Reciprocal Rank Fusion (BM25, vector, recency, feedback, confidence). Graph-aware search layers on top: a bidirectional adjacency index links related memories, Personalized PageRank scores multi-hop traversal paths, and reserved slot injection guarantees graph-only results in top-k. Scope-safe subgraph filtering prevents cross-prefix leakage. An event bus streams mutations via SSE and webhooks. An append-only audit log tracks every change with evidence strength badges.
The temporal reasoning engine adds stable date metadata. Each memory can carry a document_at ISO 8601 date for when the source content was created, independent of system timestamps. Updates preserve history by archiving the old version with a supersedes link and an is_latest flag, so no data is lost. Date-range filters (since/until) work across all search methods. Reinforcement events update last_reinforced_at without touching updated_at, keeping content and usage signals separate.
The optional extraction pipeline uses an LLM (Anthropic, OpenAI, Ollama, or ChatGPT Subscription) to analyze conversation transcripts and classify facts through the AUDN loop before storing them. Extraction now also creates related_to graph edges between new memories and similar existing ones, with relevance scores guiding link creation. Lifecycle policies enforce per-prefix TTL and confidence-based auto-archive.
The Claude Code plugin is the primary integration path. It packages the full 12-hook lifecycle (session start, every prompt, after response, pre/post-compact, subagent start/stop, tool use, tool observation, file write guard, config change, session end), skills, and CLAUDE.md into a single installable unit. The plugin auto-updates via dk-marketplace, and the /memories:setup skill handles backend provisioning and MCP configuration interactively. A standalone docker-compose.standalone.yml enables zero-clone deployment — no git clone needed. Extraction fires unconditionally with widened capture windows (4 message pairs / 8K chars for responses, 12 messages / 8K for subagents), letting the AUDN LLM decide what’s worth keeping. SubagentStart recall injects project memories into Plan, Explore, code-reviewer, and general-purpose subagents at spawn. PostToolUse observation logs Write/Edit/Bash tool usage to the session file for richer extraction context.
The Memories Skill wraps the MCP tools with a disciplined workflow: proactively searching memories before asking clarifying questions, using memory_add for simple novel facts and memory_extract for complex multi-fact conversations or lifecycle decisions (updates, deletions, reversals). Source prefixes like claude-code/{project} and learning/{project} keep memories organized across projects.